收稿日期:2019-03-28
作者简介:巩岩博(1994—),男,硕士,研究领域为液体火箭发动机系统仿真
作者简介:巩岩博(1994—),男,硕士,研究领域为液体火箭发动机系统仿真
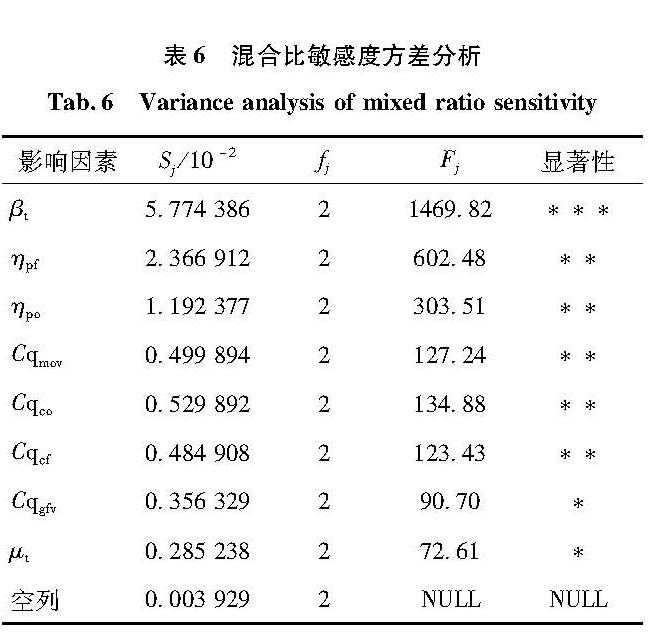
为了弥补极差分析法在发动机性能敏感性分析方面的不足,提高低温火箭发动机性能敏感性分析的准确度,引入了方差分析法,以某型液氧/甲烷发动机为例开展了性能敏感性分析,并通过F检验得到了每个干扰因素对发动机性能影响的显著性指标,与传统的极差分析法相比,提高了液体火箭发动机性能敏感性分析的准确度。结果 表明:发动机推力和混合比对同一因素的敏感性存在差别,其中对发动机推力和混合比的影响最大的是涡轮泵效率,均呈现高度显著; 紧随其后,对推力影响显著性最高的是副系统流阻特性,而对混合比影响最高的则是主系统流阻特性。研究表明,方差分析法可以有效提高敏感性分析的准确度,既为该型发动机的研制提供了理论支持,也为其他发动机的敏感性分析提供了新的参考。
In order to make up for the deficiency of range analysis method in engine performance sensitivity analysis and improve the accuracy of performance sensitivity analysis of cryogenic rocket engine, variance analysis method was introduced in this paper.Taking a liquid oxygen/methane engine for example, performance sensitivity analysis was carried out, and the significance index of each interference factor on engine performance was obtained through F test.Compared with the traditional range analysis method, the variance analysis method improves the accuracy of performance sensitivity analysis of liquid rocket engine.The results show that the sensitivity of engine thrust and mixing ratio to the same factor is different, among which the turbopump efficiency has the greatest influence on both engine thrust and mixing ratio.The second most significant impact on thrust is the flow resistance characteristics of the subsystem, while the second most significant impact on mixing ratio is the flow resistance characteristics of the main system.The results of this study show that ANOVA can effectively improve the accuracy of sensitivity analysis, which not only provides theoretical support for the development of this type of engine, but also provides a new reference for sensitivity analysis of other engines.